





Nvidia has fleshed out a complete software stack to ease custom model development and deployment for enterprises. Is this AI Nervana? And can AMD and Intel compete with this?
In order for enterprises to adopt AI, its got to become a lot easier and more affordable. Nvidia has (re-) launched AI Foundry to help Enterprises adapt and adopt AI to meet their business needs without having to start from scratch. And without having to spend gazillions of dollars.
The timing is spot-on as investors grow nervous that it may be hard for enterprises to make a good return on their AI investments. And without Enterprise adoption, AI will fail and we will be back to an AI Winter. To counter that narrative, Nvidia is expected to share Enterprise ROI stories during its next earnings call. And the new AI Foundry coupled with NIMs could become the standard path forward for most companies. While many components of this story are indeed open source, they only run on Nvidia GPUs. I know of no other chip company with anything even close to NIMs or the AI Foundry.
What is the AI Foundry?
The Nvidia AI Foundry is a combination of software, models, and expert services to help Enterprises not only get started, but complete their AI journey. Will this put Nvidia on a collision course with its ecosystem consulting partners such as IBM and Accenture? Accenture has been using the Nvidia AI Foundry to revamp its internal enterprise functions, and has now taken what they have learned and created the Accenture AI Refinery to help its clients do the same. Deloitte is on a similar path.
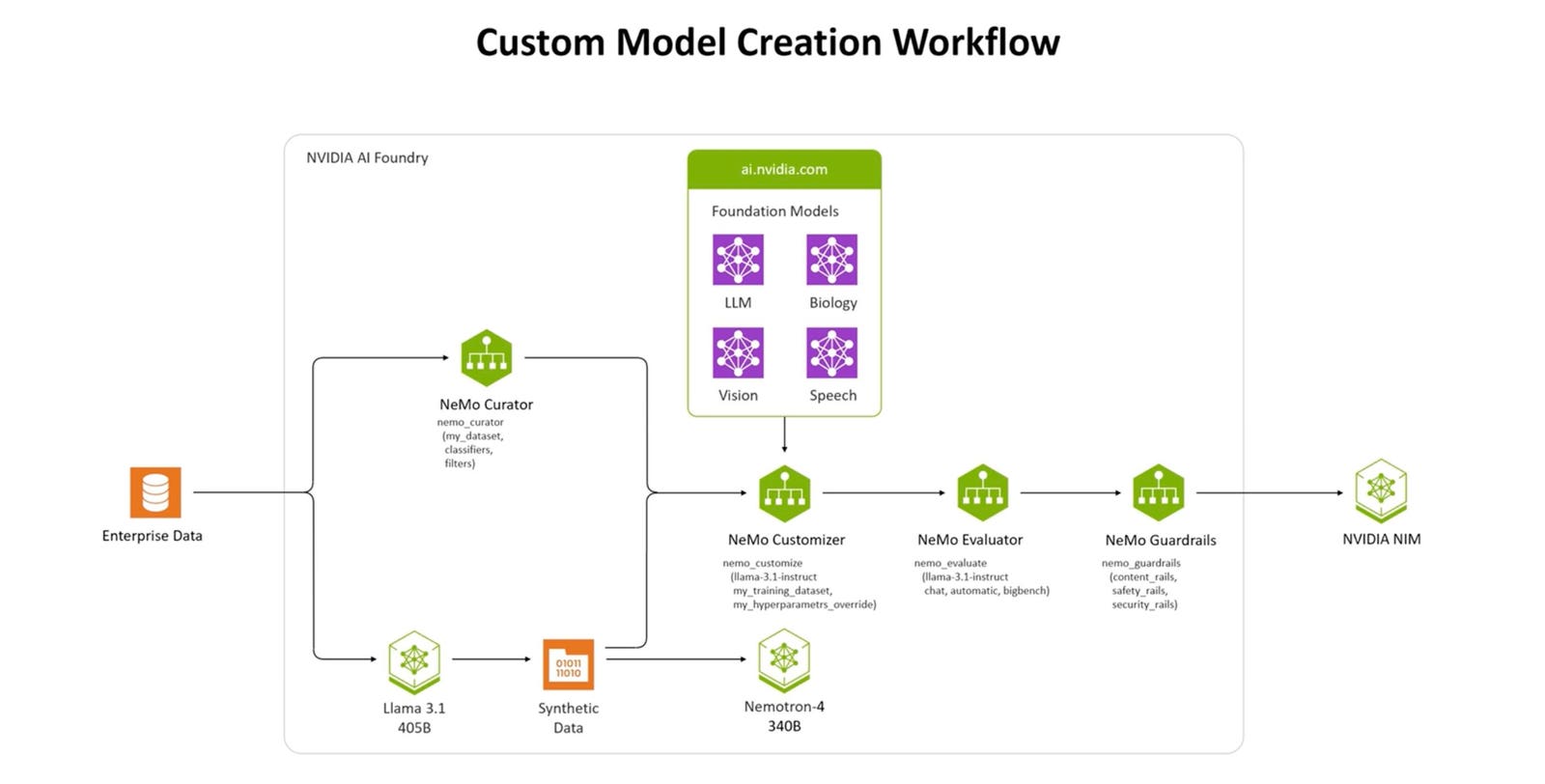
The custom model creation workflow.
NVidia
According to Nvidia’s blog on the Foundry, “Just as TSMC manufactures chips designed by other companies, NVIDIA AI Foundry provides the infrastructure and tools for other companies to develop and customize AI models — using DGX Cloud, foundation models, NVIDIA NeMo software, NVIDIA expertise, as well as ecosystem tools and support.”
When initially rolled out back in late 2023, Nvidia Foundry was focussed on Microsoft Azure hosted AI. Since then, Nvidia has recruited dozens of partners to help deliver the platform, including AWS, Google Cloud, and Oracle Cloud as well as scores of generative AI companies, model builders, integrators and OEMs.
The ecosystem for Nvidia AI Foundry has exploded with new partners,
Nvidia
The NVIDIA AI foundry service pulls together three elements needed to customize a model for a specific data set or company — a collection of NVIDIA AI Foundation Models, NVIDIA NeMo framework and tools, and NVIDIA DGX Cloud AI supercomputing services — giving enterprises an end-to-end solution for creating custom generative AI models.
But you thought thats what RAG was for, right? Yes, Retrieval Augmented Generation can do a great job of adding company-specific data to an LLM. But Nvidia said that the Foundry can produce a customized model that is fully ten points more accurate than a simple RAG augmentation. Ten points can make the difference between a great model and one that may be thrown on the trash heap.
And NIMs
NIMs provide the building blocks needed to greatly simplify and expand the domains that the Foundry can build on. Nvidia shared over 50 NIMs they have already created for various domains. Recall that a NIM is a containerized inference processing micro-service that the Nvidia NIM Factory has built, and that an Enterprise AI License provides access to the ever-growing NIM Library on ai.nvidia.com.
Nvidia NIMs are multiplying rapidly and cover most of the major modes of data and AI.
Nvidia
The Foundry launch was timed to coincide with Meta’s release of Llama 3.1 405B, which is the first open model that can rival the top AI models from OpenAI, Google, and others, when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and now with multilingual translation. Meta believes the latest generation of Llama will ignite new applications and modeling paradigms, including synthetic data generation to enable the improvement and training of smaller models, as well as model distillation. Nvidia Foundry also supports the NVIDIA Nemotron, CodeGemma by Google DeepMind, CodeLlama, Gemma by Google DeepMind, Mistral, Mixtral, Phi-3, StarCoder2 and others.
And true to form, Nvidia shows that it can increased performance of models like Llama 3.1 with optimized NIMs. Inferencing solutions like NVIDIA TensorRT-LLM improve efficiency for Llama 3.1 models to minimize latency and maximize throughput, enabling enterprises to generate tokens faster while reducing total cost of running the models in production.
For Llama 3.1 from Meta, NIMs deliver higher performance on the same hardware,
Nvidia
Nvidia also released today four new NeMo Retriever NIM microservices to enable enterprises to scale to “agentic AI” workflows — where AI applications operate accurately with minimal intervention or supervision — while delivering the highest accuracy retrieval-augmented generation, or RAG. These new NeMo Retriever embedding and reranking NIM microservices are now generally available:
NV-EmbedQA-E5-v5, a popular community base embedding model optimized for text question-answering retrieval
NV-EmbedQA-Mistral7B-v2, a popular multilingual community base model fine-tuned for text embedding for high-accuracy question answering
Snowflake-Arctic-Embed-L, an optimized community model, and
NV-RerankQA-Mistral4B-v3, a popular community base model fine-tuned for text reranking for high-accuracy question answering.
“NeMo Retriever provides the best of both worlds. By casting a wide net of data to be retrieved with an embedding NIM, then using a reranking NIM to trim the results for relevancy, developers tapping NeMo Retriever can build a pipeline that ensures the most helpful, accurate results for their enterprise,” Nvidia explained in their blog.
A NIM Example: A Healthcare Chatbot
Perhaps an example would help. Suppose you want to build a digital assistant to help patients with personalized information. Nvidia showed how they can combine 3 agents and 9 NIMs to build an assistant application. This is pretty close to Nervana and way beyond anything that the competition can offer.
A collection of NIMs can be used to create a healthcare digital assistant.
Nvidia
Conclusions
While the competition continues to improve the performance and connectivity of their accelerators, Nvidia is building the software that enables AI adoption. I know of no competitor to NIMs, nor a competitor to Foundry. And of course, nobody has introduced a competitor to Transformer Engine nor TensorRT-LLM, both of which can deliver 2-4 times the performance of a GPU without these features.
As enterprises work to adapt and adopt custom models for their business and applications, Nvidia is providing an easy on ramp to become an AI-enabled enterprise.
As for pricing, while NIM is included in the Enterprise AI license for each GPU, Foundry is priced based on a specific customer situation and is not included in Enterprise AI.
Here’s more detail on the Foundry:
NVIDIA BlogHow NVIDIA AI Foundry Lets Enterprises Forge Custom Generative AI Models
>>> Read full article>>>
Copyright for syndicated content belongs to the linked Source : Forbes – https://www.forbes.com/sites/karlfreund/2024/07/23/nvidia-ai-foundry-and-nims-a-huge-competitive-advantage


{kind=link}