






Artificial intelligence researchers were able to successfully create a machine learning model capable of learning words using footage captured by a toddler wearing a headcam. The findings, published this week in Science, could shed new light on the ways children learn language and potentially inform researchers’ efforts to build future machine learning models that learn more like humans.
Previous research estimates children tend to begin acquiring their first words around 6 to 9 months of age. By their second birthday, the average kid possesses around 300 words in their vocabulary toolkit. But the actual mechanics underpinning exactly how children come to associate meaning with words remains unclear and a point of scientific debate. Researchers from New York University’s Center for Data Science tried to explore this gray area further by creating an AI model that attempted to learn the same way a child does.
To train the model, the researchers relied on over 60 hours of video and audio recordings pulled from a light head camera strapped to a child named Sam. The toddler wore the camera on and off starting when he was six months old and ending after his second birthday. Over those 19 months, the camera collected over 600,000 video frames connected to more than 37,500 transcribed utterances from nearby people. The background chatter and video frames pulled from the headcam provides a glimpse into the experience of a developing child as it eats, plays, and generally experiences the world around them.
Short video clip captured from a head-mounted camera. Credit: Video courtesy of Sam’s dad.
Armed with Sam’s eyes and ears, the researchers then created a neural network model to try and make sense of what Sam was seeing and hearing. The model, which had one module analyzing single frames taken from the camera and another focused on transcribed speech direct towards Sam, was self-supervised, which means it didn’t use external data labeling to identify objects. Like a child, the model learned by associating words with particular objects and visuals when they happened to co-occur at the same time.
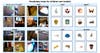 Testing procedure in models and children. Credit: Wai Keen Vong
Testing procedure in models and children. Credit: Wai Keen Vong
“By using AI models to study the real language-learning problem faced by children, we can address classic debates about what ingredients children need to learn words—whether they need language-specific biases, innate knowledge, or just associative learning to get going,” paper co-author and NYU Center for Data Science Professor Brenden Lake said in a statement. “It seems we can get more with just learning than commonly thought.”
Researchers tested the model the same way scientists evaluate children. Researchers presented the model with four images pulled from the training set and asked it to pick which one matches with a given word like “ball” “crib” or “tree.” The model was successful 61.6% of the time. The baby cam-trained model even approached similar levels of accuracy to a pair of separate AI models that were trained with many more language inputs. More impressive still, the model was able to correctly identify some images that weren’t included in Sam’s headcam dataset, which suggests it was able to learn from the data it was trained on and use that to make more generalized observations.
“These findings suggest that this aspect of word learning is feasible from the kind of naturalistic data that children receive while using relatively generic learning mechanisms such as those found in neural networks,” Lake said.
In other words, the AI model’s ability to consistently identify objects using only data from the head camera shows how representative learning, or simply associating visuals with concurrent words, does seem to be enough for children to learn and acquire a vocabulary.
Findings hint at an alternative method to train AI
Looking to the future, the NYU researchers’ findings could prove valuable for future AI developers interested in creating AI models that learn in ways similar to humans. The AI industry and computer scientists have long used human thinking and neural pathways as inspiration for building AI systems.
Recently, large language models like OpenAI’s GPT models or Google’s Bard have proven capable of writing serviceable essays, generating code, and periodically botching facts thanks to an intensive training period where the models inject trillions of parameters worth of data pulled from mammoth datasets. The NYU findings, however, suggest an alternative method of word acquisition may be possible. Rather than rely on mounds of potentially copyright protected or biased inputs, an AI model mimicking the way humans learn when we crawl and stumble our way around the world could offer an alternative path towards recognizing language.
“I was surprised how much today’s AI systems are able to learn when exposed to quite a minimal amount of data of the sort a child actually receives when they are learning a language,” Lake said.
>>> Read full article>>>
Copyright for syndicated content belongs to the linked Source : Popular Science – https://www.popsci.com/technology/baby-headcam-ai-learn/


{kind=link}