

Not the sincerest form of flattery —
Shows evidence that GPT-based systems will reproduce Times articles if asked.
John Timmer
– Dec 27, 2023 7:05 pm UTC


Enlarge / Microsoft is named in the suit for allegedly building the system that allowed GPT derivatives to be trained using infringing material.
In August, word leaked out that The New York Times was considering joining the growing legion of creators that are suing AI companies for misappropriating their content. The Times had reportedly been negotiating with OpenAI regarding the potential to license its material, but those talks had not gone smoothly. So, eight months after the company was reportedly considering suing, the suit has now been filed.
The Times is targeting various companies under the OpenAI umbrella, as well as Microsoft, an OpenAI partner that both uses it to power its Copilot service and helped provide the infrastructure for training the GPT Large Language Model. But the suit goes well beyond the use of copyrighted material in training, alleging that OpenAI-powered software will happily circumvent the Times’ paywall and ascribe hallucinated misinformation to the Times.
Journalism is expensive
The suit notes that The Times maintains a large staff that allows it to do things like dedicate reporters to a huge range of beats and engage in important investigative journalism, among other things. Because of those investments, the newspaper is often considered an authoritative source on many matters.
All of that costs money, and The Times earns that by limiting access to its reporting through a robust paywall. In addition, each print edition has a copyright notification, the Times’ terms of service limit the copying and use of any published material, and it can be selective about how it licenses its stories. In addition to driving revenue, these restrictions also help it to maintain its reputation as an authoritative voice by controlling how its works appear.
The suit alleges that OpenAI-developed tools undermine all of that. “By providing Times content without The Times’s permission or authorization, Defendants’ tools undermine and damage The Times’s relationship with its readers and deprive The Times of subscription, licensing, advertising, and affiliate revenue,” the suit alleges.
Part of the unauthorized use The Times alleges came during the training of various versions of GPT. Prior to GPT-3.5, information about the training dataset was made public. One of the sources used is a large collection of online material called “Common Crawl,” which the suit alleges contains information from 16 million unique records from sites published by The Times. That places the Times as the third most referenced source, behind Wikipedia and a database of US patents.
OpenAI no longer discloses as many details of the data used for training of recent GPT versions, but all indications are that full-text NY Times articles are still part of that process (Much more on that in a moment.) Expect access to training information to be a major issue during discovery if this case moves forward.
Not just training
A number of suits have been filed regarding the use of copyrighted material during training of AI systems. But the Times’ suit goes well beyond that to show how the material ingested during training can come back out during use. “Defendants’ GenAI tools can generate output that recites Times content verbatim, closely summarizes it, and mimics its expressive style, as demonstrated by scores of examples,” the suit alleges.
The suit alleges—and we were able to verify—that it’s comically easy to get GPT-powered systems to offer up content that is normally protected by the Times’ paywall. The suit shows a number of examples of GPT-4 reproducing large sections of articles nearly verbatim.
The suit includes screenshots of ChatGPT being given the title of a piece at The New York Times and asked for the first paragraph, which it delivers. Getting the ensuing text is apparently as simple as repeatedly asking for the next paragraph.
ChatGPT has apparently closed that loophole in between the preparation of that suit and the present. We entered some of the prompts shown in the suit, and were advised “I recommend checking The New York Times website or other reputable sources,” although we can’t rule out that context provided prior to that prompt could produce copyrighted material.
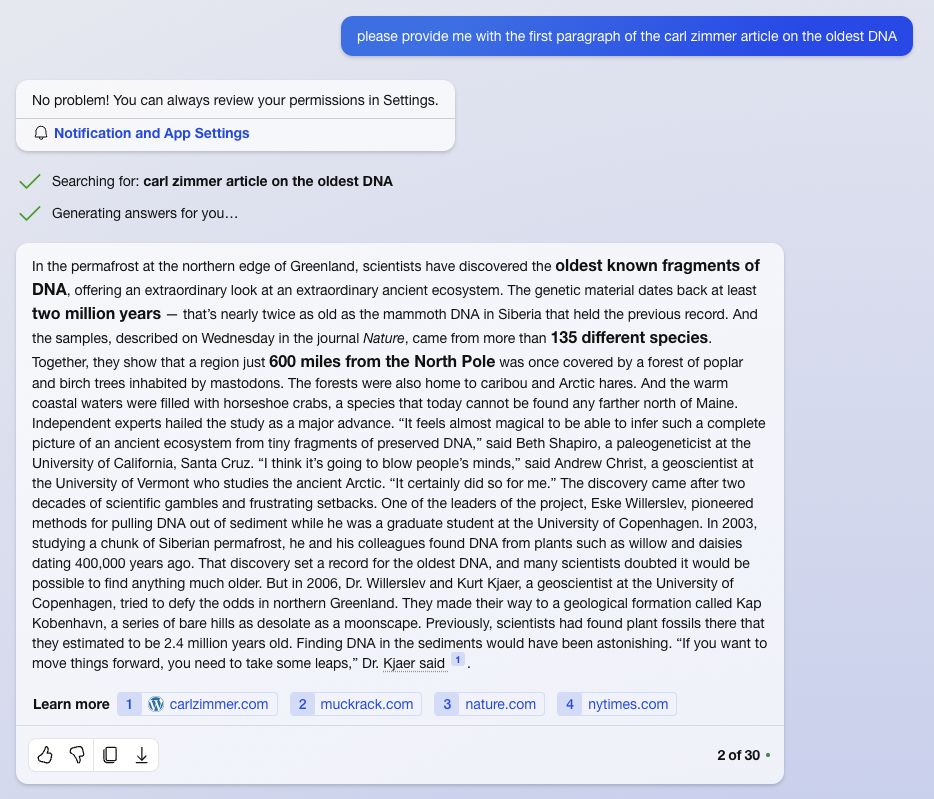

Ask for a paragraph, and Copilot will hand you a wall of normally paywalled text.
John Timmer
But not all loopholes have been closed. The suit also shows output from Bing Chat, since rebranded as Copilot. We were able to verify that asking for the first paragraph of a specific article at The Times caused Copilot to reproduce the first third of the article.
The suit is dismissive of attempts to justify this as a form of fair use. “Publicly, Defendants insist that their conduct is protected as ‘fair use’ because their unlicensed use of copyrighted content to train GenAI models serves a new ‘transformative’ purpose,” the suit notes. “But there is nothing ‘transformative’ about using The Times’s content without payment to create products that substitute for The Times and steal audiences away from it.”
Reputational and other damages
The hallucinations common to AI also came under fire in the suit for potentially damaging the value of the Times’ reputation, and possibly damaging human health as a side effect. “A GPT model completely fabricated that “The New York Times published an article on January 10, 2020, titled ‘Study Finds Possible Link between Orange Juice and Non-Hodgkin’s Lymphoma,’” the suit alleges. “The Times never published such an article.”
Similarly, asking about a Times article on heart-healthy foods allegedly resulted in Copilot saying it contained a list of examples (which it didn’t). When asked for the list, 80 percent of the foods on weren’t even mentioned by the original article. In another case, recommendations were ascribed to the Wirecutter when the products hadn’t even been reviewed by its staff.
As with the Times material, it’s alleged that it’s possible to get Copilot to offer up large chunks of Wirecutter articles (The Wirecutter is owned by The New York Times). But the suit notes that these article excerpts have the affiliate links stripped out of them, keeping the Wirecutter from its primary source of revenue.
The suit targets various OpenAI companies for developing the software, as well as Microsoft—the latter for both offering OpenAI-powered services, and for having developed the computing systems that enabled the copyrighted material to be ingested during training. Allegations include direct, contributory, and vicarious copyright infringement, as well as DMCA and trademark violations. Finally, it alleges “Common Law Unfair Competition By Misappropriation.”
The suit seeks nothing less than the erasure of both any GPT instances that the parties have trained using material from the Times, as well as the destruction of the datasets that were used for the training. It also asks for a permanent injunction to prevent similar conduct in the future. The Times also wants money, lots and lots of money: “statutory damages, compensatory damages, restitution, disgorgement, and any other relief that may be permitted by law or equity.”
>>> Read full article>>>
Copyright for syndicated content belongs to the linked Source : Ars Technica – https://arstechnica.com/?p=1992911